Automated Kubernetes deployment with Helm and additional templating

Hi! My name is Mikhail and I am CTO at Exerica and Deputy CEO at Qoollo. At Exerica, we have built a system with a service oriented architecture (SOA): more than a dozen services, a NoSQL database and centralised logging with monitoring.
In this article I will explain how we can build and configure a system of (micro) services automatically deployed with Kubernetes, using Helm and some additional tools, and not get lost in a variety of templates and manifests. We have successfully implemented this approach and if you have a similar type of problem to deal with, I hope the article will be useful for you — both as an approach in itself, but also as a source of ideas which can be adapted for a variety of approaches.
About the system and the deployment task we faced
We use our own GitLab platform to work with code and CI / CD. Each application has its own repository, where it is developed, with the registry containing the docker images of the application. This means the system generates the version number, and the developer specifies only the major or minor versions. Feature versions which aren’t necessarily core developments can also be automatically added from the issue number in the tracker.
We usually have numerous deployments to a production environment per day. On top of that, almost every developer deploys a fully functional version of the system. That means we need a simple framework in which we can build a system from a set of services with specific versions — as well as a convenient automatic process enabling us to roll back changes if something goes wrong. We have previously automated deploying to a Docker Swarm cluster using Ansible.

Our Docker Swarm experience
Our Docker Swarm setup worked well for several years, but, over time, more and more problems started to arise:
- Low fault tolerance with one input Nginx reverse proxy
- As the number of applications grew, many of the same type of playbooks and template files for Docker Swarm services appeared, and it became difficult to maintain them
- Performance drawdowns of the Docker Swarm overlay network: periodically, for no apparent reason, it dropped to several megabits / s on gigabit links
- Lack of flexibility in resource management for applications
- Inconvenient management of external DNS for published services through the custom Ansible module
- Inconvenient management of TLS certificates
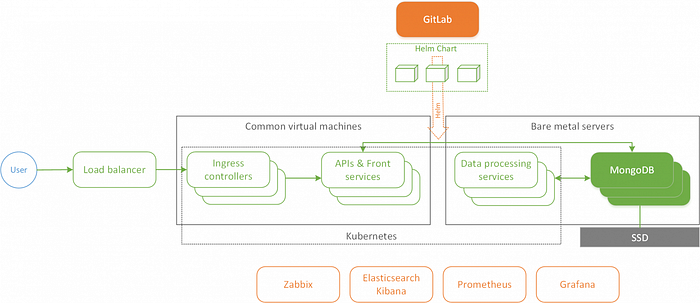
Because of these issues, we decided to transfer the system to self-managed Kubernetes cluster. When making this transition we also set ourselves the task of automating the generation of manifests for applications and resources as much as possible. Ideally, for standard cases, the inclusion of a service in the system should require that the developer only needs to specify its configuration, resource restrictions and service placement. We left stateful services: the database, services for monitoring and collecting logs as they are, outside Kubernetes.
The transition to Kubernetes
In making the transition to Kubernetes, we decided not to fundamentally change the build and deployment process. Historically, we had a separate git repository (deployment repository), containing all scripts and deployment configs. Deployment is performed with Gitlab CI jobs. When the CI pipeline of the develop branch is launched, the production environment is deployed, and when the pipeline for the branch associated with the issue in the tracker (starts with a unique number), the test environment is deployed. The same branch number is used to identify test environments.
The minimum thing a release manager or developer needs to do is write down the required versions of the applications and apply commit. The rest of the process is done by the Gitlab CI pipeline. Successful completion indicates that the deployment is complete and the deployed system is operational.
Choice of tools and the meaning of a ‘chart’
A very handy tool making it possible to implement almost all of the above requirements is Helm, a package manager for Kubernetes. As written on the helm.sh website:
Helm Helps Manage Kubernetes Applications — Helm Charts help you identify, install, and update even the most complex Kubernetes application.
Helm allows you to describe both individual applications and systems as a whole as what they call “charts” or packages. Very briefly, a ‘chart’ is a set of files containing templates and parameters, from which Helm builds manifests for all the necessary Deployment, Service, Ingress, ConfigMap, and other Kubernetes objects. Ample opportunities for templating allow you to define a fairly universal template and follow the DRY principle.
Helm allows managing the deployment process, as well as making it atomic (meaning it updates correctly or the new installation is deleted upon failure) and reversible. The deployment is started with a single helm update command. If the deployment process fails, Helm can be automatically rolled back, with a single Helm rollback command, returning everything in the system to the corresponding previous state.
You can read more about Helm in the official documentation.
Chart structure
The first requirement is to formulate the basic principles underlying the deployment architecture:
- The deployment of the system is described by a single chart (the so-called umbrella chart) to enable expansion and atomic roll back.
- The system chart should contain the minimum number of defined objects, to maintain loose coupling of applications.
- The deployment of each application is described in its own chart (the subchart), allowing us to independently modify applications.
- Each application has its own unique name, enabling easy identification of associated parameters. Using the application name, other applications can obtain the necessary parameters for communication (for example, a service name).
- An ingress defined for the application should use subdomain, and not the path. This rule makes it easier to template a definition for ingress, but can be dropped if needed.
- The application chart should ideally not contain other applications as dependencies (the exception is for sidecar containers).
- Follow DRY: if some part of the manifest or template is universal, it should be moved to a higher level of abstraction. The goal is clear — to have one point of change.
- Minimize references to global parameters of the main chart (
.Values.global), especially if these parameters relate to a specific application. Ideally, they shouldn’t exist at all. This allows the elimination of difficult-to-manage implicit dependencies. - All application configuration parameters and other variables (for example, DNS-names of services) are located in only one place — a single system configuration file, from which all applications receive configuration.
- Charts do not contain secrets (although they could) and they are not under the control of Helm. We did this deliberately, to keep the secret management and deployment processes separate.
- Charts are not intended to be posted on public resources and individual applications may not be functional outside the system.
From applying these, we should get one chart with one level from several subcharts. We have moved the definition and assembly of the chart for each application into a separate repository, along with the main chart. This made it possible to reuse unified templates, as I’ll discuss next.
Chart building process
As I mentioned earlier, Helm has many templating capabilities. However, for several reasons, in our circumstances, it was not enough. First, it is not possible to template the versions in the Chart.yaml file. Second, the values.yaml files cannot contain templates. There is a workaround for this via the tpl function, however it is not convenient in all cases and has performance issues. Sometimes it is easier and more understandable to write templated values in the form of placeholder text, for example:
host: "api-%envTag%.somedomain.com"The resulting yaml with substituted values can be obtained with a single call to sed.
Also, as a tool for external templating, it is convenient to use the yq utility to insert, replace values and merge yaml files.
The algorithm for assembling the entire chart is performed automatically and in general looks like this:
- Putting together a subchart for each application using standard templates.
- We put the current versions in all
Chart.yaml. - Based on the templates, building values.yaml for the main chart.
- Generate a unique version of the system and insert it into
Chart.yamlfor the main chart. - Run the build and get the system release described by the chart.
In the course of the description, I will omit some “technical” parts and details that are either tied to our system, or can be easily supplemented by the reader.
Main chart and single configuration
First, let’s create directories for the main chart, subcharts and standard templates.
mkdir oursystem # Main chart
mkdir subcharts # Charts for apps
mkdir templates # Reusable (typical) templates
mkdir templates/subchart # Typical templates for chart applicationsWe decided that to avoid confusion, the name of the directory of the main chart should be its name, it will be underneath that, it will be placed in the repository, and will be used in the Helm commands. We have it called exerica, here I will use oursystem. Let’s create the following structure for it:
oursystem/
├── .helmignore
├── Chart.yaml
└── templates/
├── _helpers.tpl
├── configmap.yaml
└── NOTES.txtThere are very few files here, since this chart only defines:
- dependencies in
Chart.yaml - common named templates in
_helpers.tpl - a single system config in
configmap.yaml - a message that will be displayed after system deployment (
NOTES.txt)
Parameters for all applications will be generated by the script during assembly and written to values.yaml.
The definition of a single config from configmap.yaml is also quite small:
apiVersion: v1
kind: ConfigMap
metadata:
name: oursystem-config
data:
{{- include "toPropertiesYaml" .Values.global.configuration | indent 2 }}The toPropertiesYaml template converts an arbitrary yaml into an array of key-value pairs, where the key is formed as a sequence of keys on the path from the root of the yaml object:
{{- define "joinListWithComma" -}}
{{- $local := dict "first" true -}}
{{- range $k, $v := . -}}{{- if not $local.first -}}, {{ end -}}{{ $v -}}{{- $_ := set $local "first" false -}}{{- end -}}
{{- end -}}{{- define "toPropertiesYaml" }}
{{- $yaml := . -}}
{{- range $key, $value := $yaml }}
{{- if kindIs "map" $value -}}
{{ $top:=$key }}
{{- range $key, $value := $value }}
{{- if kindIs "map" $value }}
{{- $newTop := printf "%s.%s" $top $key }}
{{- include "toPropertiesYaml" (dict $newTop $value) }}
{{- else if kindIs "slice" $value }}
{{ $top }}.{{ $key }}: {{ include "joinListWithComma" $value | quote }}
{{- else }}
{{ $top }}.{{ $key }}: {{ $value | quote }}
{{- end }}
{{- end }}
{{- else if kindIs "slice" $value }}
{{ $key }}: {{ include "joinListWithComma" $value | quote }}
{{- else }}
{{ $key }}: {{ $value | quote }}
{{- end }}
{{- end }}
{{- end }}
Let’s create a versions.yaml file that defines the versions of the applications that we will deploy.
# Application versions
versions:
webapi: "1.36.4082"
analytics: "0.1.129"
publicapi: "0.1.54"
# The same way for every application
...
# Application deployment conditions
conditions:
webapi:
enabled: true
analytics:
enabled: true
redis:
enabled: true
...All configuration parameters that will be transferred to a single system config will be defined in the one file, templates/variables.yaml.
common:
envTag: "%envTag%"
envName: "oursystem-%envTag%"
internalProtocol: http
externalProtocol: https
...
webapi:
name: webapi
host: "api-%envTag%.somedomain.com"
path: "/api/v2"
analytics:
name: analytics
host: "analytics-%envTag%.somedomain.com"
path: "/api/v1"
redis:
name: redis
serviceName: redis-master
internalProtocol: redis
...Later in the build process, some “derivative” values are added to these parameters which are also needed to configure applications, for example, the full URL for ingress: ingressUrl. When assembling the main chart, these parameters will be inserted into the .Values.global.configuration section and will form a ConfigMap with a single system config. In particular, we will refer to them in environment variables for containers.
This means we can pass parameters to the webapi application through environment variables, for example:
DEPLOY_ENVIRONMENT— the global name of the environment in which the application operates, taken from thecommon.envNameparameterProcessingRemoteConfiguration__RemoteAddress— the address of the service with which the webapi application interacts, taken from theprocessing.serviceUrlparameter
Env section from subcharts/webapi/values.yaml
env:
- name: DEPLOY_ENVIRONMENT
valueFrom:
configMapKeyRef:
name: oursystem-config
key: "common.envName"
- name: ProcessingRemoteConfiguration__RemoteAddress
valueFrom:
configMapKeyRef:
name: oursystem-config
key: "processing.serviceUrl"
...Environment variables are read and passed to the application when it starts up. If, during the deployment of the next version of the system, some application has not changed, but the system configuration has changed, then it will not be restarted. To solve this problem, it is convenient to use the Reloader controller, which tracks changes to ConfigMap, Secret objects, and performs a rolling update for pods that depend on them. We included it in the system as an external dependency through the Helm chart. In our approach, this is done literally in a few lines.
Adding an “external” application to the system
To oursystem/Chart.yaml
...
dependencies:
...
- name: reloader
version: ">=0.0.89"
repository: https://stakater.github.io/stakater-charts
condition: reloader.enabled
...To versions.yaml
...
conditions:
...
reloader:
enabled: true
...Template unification
Let’s create the first subchart using the helm scaffolding (the name must match the application name).
helm create subcharts/webapiWe get a directory with the following files:
webapi/
├── .helmignore
├── Chart.yaml
├── values.yaml
├── charts/
└── templates/
├── tests/
├── _helpers.tpl
├── deployment.yaml
├── hpa.yaml
├── ingress.yaml
├── NOTES.txt
├── service.yaml
└── serviceaccont.yamlThe purpose of all these files is perfectly described in the official documentation. Let’s pay attention to the templates directory: all templates in it, generally speaking, are weakly dependent on the application. In order not to violate DRY, we will place them in templates/subchart:
mv subcharts/webapi/templates* templates/subchartYou can delete unnecessary templates here. For example, you can choose not to use NOTES.txt for individual applications. I will also omit everything related to tests. If necessary, templating tests can be implemented in the same way.
Let’s create a templates/resources.yaml file, in which we will collect all the definitions for the resources allocated to applications. Single app section in this file would look like:
...
webapi:
replicaCount: 2
resources:
limits:
cpu: 6
memory: 4Gi
requests:
cpu: 500m
memory: 512Mi
...All fixed parameters for values.yaml will be collected in a separate file values.templ.yaml, such as parameters for “external” dependencies, for example redis.
...
redis:
redisPort: 6379
usePassword: false
architecture: standalone
cluster:
enabled: false
slaveCount: 0
master:
extraFlags:
- "--maxmemory 1gb"
- "--maxmemory-policy allkeys-lru"
persistence:
enabled: true
size: 2Gi
metrics:
enabled: trueLet’s also move the generic definition for ingress from values.yaml to templates/values.ingress.yaml.
enabled: true
annotations:
kubernetes.io/ingress.class: nginx
hosts:
- host: "%ingressHost%"
paths:
- path: /
backend:
service:
name: "%serviceName%"
tls:
- hosts:
- "%ingressHost%"Thus, we will get the structure of template files from which a single chart of our system is then assembled:
oursystem— minimum main chartsubcharts— files of subcharts that cannot be unified, or their unification is impracticaltemplates— templates for generating parameters for all subchartstemplates/subcharts— unified helm templates for subchart objects
General structure of template files:
build_chart.sh
versions.yaml
oursystem/
├── .helmignore
├── Chart.yaml
├── templates/
│ ├── _helpers.tpl
│ ├── configmap.yaml
│ └── NOTES.txt
├── subcharts/
│ ├── analytics/
│ │ ├── Chart.yaml
│ │ └── values.yaml
│ │ ...
│ └── webapi
│ ├── Chart.yaml
│ └── values.yaml
└── templates/
├── resources.yaml
├── values.templ.yaml
├── values.ingress.yaml
├── variables.yaml
└── subchart/
├── deployment.yaml
├── hpa.yaml
├── ingress.yaml
├── service.yaml
└── serviceaccount.yamlFrom the values.*. yaml, variables.yaml and resources.yaml files from the templates directory, the values.yaml file is eventually built.
Let’s create a build script build_chart.sh that reproduces the build algorithm described above. You can find it here.
Putting everything together:
helm dependency update ./oursystem --debug
helm package ./oursystem --debugAs the result of the script we will receive a system release of a specific version: a linked chart for the entire system, which defines all the dependencies and configuration parameters for deployment in a Kubernetes cluster. If necessary during the deployment process, any main chart or subchart parameters can be overridden using the --set or -f keys.
Atomic release deployment
Deployment of the prepared release of the system is done with one command:
helm upgrade "${ENV_NAME}" "${CHART_NAME}" -i -n "${ENV_NAME}" \
--atomic --timeout 3mThe environment variables are passed:
- ENV_NAME is the name of the environment for deployment
- CHART_NAME — full name of the assembled system chart (including version)
After substitution of environment variables, the command will look something like this:
helm upgrade system-dev "system-1.2.3456.tgz" -i -n system-dev \
--atomic --timeout 3mAs can be seen, each environment has its own namespace, so even objects of the same name from different environments within the same cluster do not conflict.
The --atomic flag tells Helm to wait for --timeout 3m to successfully deploy all applications. In the event of an error or timeout expiration, an automatic rollback to the previous release will occur.
Functionality expansion options
For different environments, for example, production and test, you can create different variables.yaml, resources.yaml and include the file corresponding to the environment in the build script.
In fact, we did just that, using different parameters for production and test environments.
You can opt out of matching the names of subcharts and deployed applications. This can be useful when needing to deploy the same application with different settings within the same system.
If problems with the build performance are noticeable (and so far they are not), all the logic of build_chart.sh can be implemented in other ways without changing the approach and template formats, for example, in python.
Everything described in this article can be applied with a different approach to version control, when automatic deployment is allowed, or when a new version of each application is released. In this case, you can run the CI pipeline for building the chart and deploying by trigger. And in the script for building the chart, change the source of the current versions of applications.
The assembled chart can be used for deployment in a completely different environment — for example, to create a separate environment for a client / customer who needs data isolation, or for deployment in a customer’s infrastructure. At a minimum, it is enough to redefine the DNS names for ingress during deployment (for example, using helm install -f …). Data for connecting to the database, etc. apps get from Secret objects, which, as mentioned above, are managed separately from the chart.
Conclusion
With the help of various templating tools, we can create a solution which is quite convenient in terms of support and scalability for describing the deployment of systems in Kubernetes.
The package manager Helm offers ample opportunities for this. But if you add additional templating to generate the same type of Helm charts, or automatically compose the chart for the system as a whole, then it is quite easy to build a continuous process for deploying the system in Kubernetes, which requires minimal human participation.
At the same time, we get the ability to manage the deployment: the formation of a release from any set of specific versions of components, automatic verification of deployment success and a convenient rollback to a previous release, if required. The move to Kubernetes also enabled a wide range of solutions to automate many infrastructure tasks. For example, we used ExternalDNS to manage external DNS records, and cert-manager to manage TLS certificates.







